8.4 Data design
In the previous section we have seen machine learning approaches to the task of computer vision. But the quality of any machine learning approach rests on a sometimes overlooked cornerstone: data. Training data must be sourced, prepared, preprocessed, and often annotated. This is a costly process in terms of time and effort, but on its correctness lies the maximum real performance of the trained algorithms in the real world. As Sambasivan et al. (2021) say, an error in any step of the data pipeline propagates to further steps, compromising the accuracy and reliability of the algorithm. When approaching a novel problem, often new data must be sourced. Furthermore, the problem must be modeled, and the data annotation schema designed. Neural networks learn patterns very accurately, but we have to decide what patterns to learn, what features to discriminate and which to abstract.
This process of data engineering is a fundamental step of the expert resolution of a problem, a step where much of the domain knowledge to be used is embedded in the final system, and thus it is as much part of the solution as the system’s code and implementation.
Unfortunately, there is not a lot of SignWriting data available to us, and what can be found is not in an easily processable format. Sometimes there is an association of transcription to meaning in oral language (which doesn’t really help, since the oral word is almost never related to the sign parameters) and most of the time there is no indication whatsoever of the symbols contained in the SignWriting transcription.
This has meant that we have had to prepare our own corpus of SignWriting that can be used for machine learning or linguistic research, using data collected in a collaboration with linguists as part of a project to develop tools for the ease of SignWriting visualization: https://www.ucm.es/visse.
In the corpus, there are two types of data: logograms and graphemes. Logograms are full transcriptions, images of SignWriting which correspond to a sign. Graphemes is the name we have chosen for individual graphic components, units of linguistic information which by themselves convey some of the meaning necessary to reconstruct the sign. The full information is obtained by combining the meanings of the different graphemes while taking into account their relative position and rotation within the logogram.
The information represented by each grapheme, however, is itself complex, and tagging each of them with a single label is not enough. We want to be able to discern the different features described in Section 8.2, and so we have developed an annotation schema for our corpus, where we assign a variable number of labels to each grapheme, depending on how much information is needed.

A first label, CLASS, divides graphemes into 6 classes
of symbols, with related graphical properties and similar semantic
information: HEAD for head symbols, DIAC for
small diacritics, often used for contact information;
HAND for graphemes which represent hands, and
ARRO, STEM and ARC for
arrows.
Graphemes are then annotated with an additional tag,
SHAPE, which identifies the actual SignWriting symbol.
For HEAD and DIAC graphemes, this is enough
information, but other graphemes require more annotation.
HAND graphemes, such as the one tagged in Figure 8.5,
have an additional label, VAR, which represents the wrist
rotation (whether the hand is white, black, or half and half, see Section
8.2 about orientation). With this, the “lexical” information of a
hand grapheme is fully specified, but we still need to record the rest
of its orientation, as graphically represented by the symbol rotation
and mirroring. Rotation (ROT) can take one of 8 different
values, described with the cardinal points (N for north, NE for
northeast, etc.). If the symbol is mirrored (horizontally flipped) a
value of ‘y’ is added for the reflection (REF).
The remaining classes of graphemes, ARRO,
STEM and ARC, are those needed to represent
movements. As we saw in Figure
8.4, movement markers in SignWriting can be very complex, as well
as mixed and superposed to create compositional meaning. Nonetheless,
they can be seen as composed of different segments: the straight or
curved trajectories, or the end of movement arrow heads. Even if, from
the point of view of SignWriting, movement markers are single holistic
“symbols”, each of the segments has its own visual identity and
meaning, so in our corpus we have chosen to identify them as separate
graphemes.
Arrow heads (class ARRO) can be black, white, or not
filled, to represent which hand is moving. The body of the arrow can
then be straight (STEM) or curved (ARC).
STEMs and ARCs can be either single or
double, to represent whether the movement is parallel to the floor or
to the wall, and finally ARCs can be a full circle, half
of one, or a quarter. This is all encoded into the SHAPE,
and it is our hypothesis that with this graphemes most if not all
movement markers can be recorded. Finally, graphemes of
ARRO, STEM and ARC class can
rotate, so need an additional ROT tag.
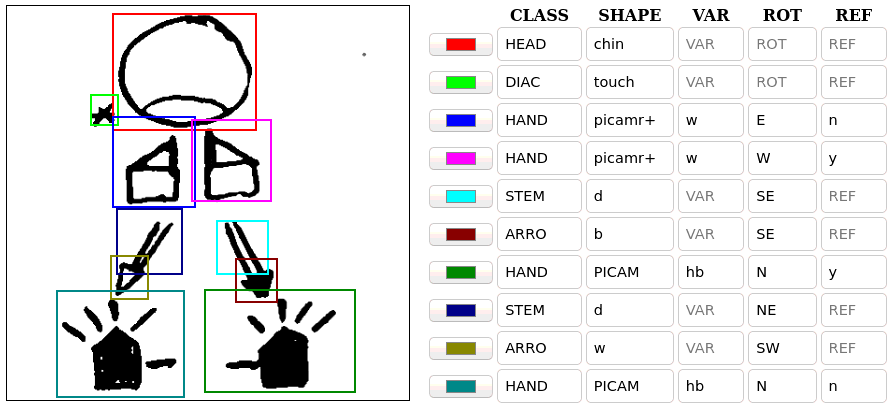
We have collected and annotated 982 handwritten logograms, within which 6071 graphemes can be found. The logogram annotation consists of the bounding boxes (location and size) of the graphemes, and then tags for each grapheme with the appropriate combination of features. An example annotation can be seen in Figure 8.6. The dataset we have created is publicly available at https://zenodo.org/record/6337885, including an annotation guide with detailed information about the different grapheme classes and their tags.